
Estimating a Multivariate GARCH Model
Estimating multivariate GARCH (MGARCH) models involves determining parameter values that best describe observed data while ensuring necessary constraints, such as the positive definiteness of the conditional covariance matrix, are satisfied. This process is typically conducted using Maximum Likelihood Estimation (MLE).
Maximum Likelihood Estimation (MLE) in a Multivariate Context
MLE is a statistical technique for estimating model parameters by maximizing the likelihood function, which represents the probability of observing given data based on specific parameter values. For MGARCH models, the likelihood function is derived from the probability density function (PDF) of the model’s error terms.
Steps in MGARCH Model Estimation Using MLE
1. Model Specification
Select the appropriate MGARCH model type, such as:
- VECH
- Diagonal VECH
- BEKK
- DCC-GARCH
Also, choose a distributional assumption for the error term, such as:
- Multivariate normal distribution
- Multivariate t-distribution (to account for fat-tailed returns)
The general MGARCH model is given by:

2. Constructing the Likelihood Function
 ]
where ( \theta ) represents the model parameters.
]
where ( \theta ) represents the model parameters.
3. Constructing the Log-Likelihood Function
To facilitate estimation, the log-likelihood function is used:
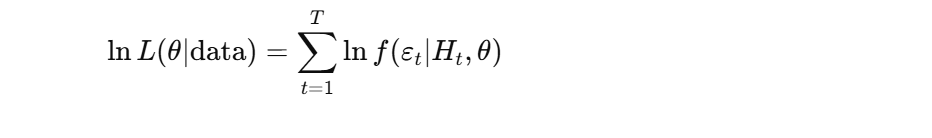 For the multivariate normal case:
For the multivariate normal case:
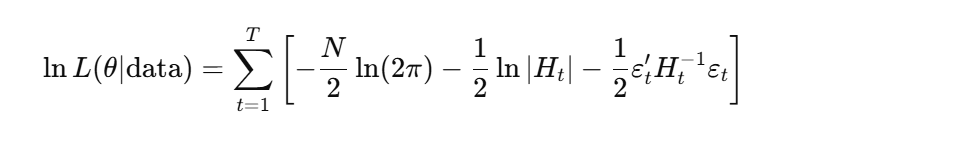
4. Maximizing the Log-Likelihood Function
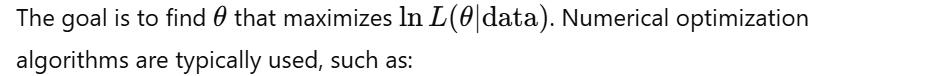
- Newton-Raphson Method
- Broyden-Fletcher-Goldfarb-Shanno (BFGS)
- Davidon-Fletcher-Powell (DFP)
Software packages like R (rugarch, rmgarch), Python (arch), and EViews provide automated functions for estimating MGARCH models.
5. Ensuring Convergence
The optimization process must converge to a solution. This is verified using convergence criteria and stability checks on estimated parameters.
6. Calculating Standard Errors
Standard errors of estimated parameters are obtained from the Hessian matrix (matrix of second derivatives of the log-likelihood function). These help in statistical inference and hypothesis testing.
7. Model Diagnostics
Post-estimation diagnostics assess the model’s adequacy:
- Residual Analysis: Standardized residuals should exhibit white noise behavior.
- Goodness-of-Fit Tests: Statistical tests can assess how well the model fits the data.
Important Considerations
- Starting Values: Poor initialization may lead to non-convergence; multiple starting values can improve robustness.
- Constraints: Parameters must ensure ( H_t ) remains positive definite.
- Robustness: Testing parameter stability across different datasets enhances reliability.
- Sample Size: Large datasets improve parameter estimation accuracy.
Challenges in Estimation
- Computational Complexity: MGARCH models are computationally intensive, particularly for large datasets.
- Parameter Proliferation: Some specifications (e.g., VECH) involve numerous parameters, leading to overfitting.
- Positive Definiteness: Ensuring ( H_t ) is always positive definite is critical for model validity.
Software Implementation
-
R: Packages such as
rugarchandrmgarchsupport MGARCH estimation. -
Python: The
archlibrary offers limited MGARCH functionality. - EViews: A commercial solution for MGARCH estimation.
Conclusion
MGARCH models provide a powerful framework for modeling time-varying covariances. Estimation requires defining the model, constructing the likelihood function, and applying MLE through numerical optimization. Careful consideration of constraints, distributional assumptions, and computational feasibility is necessary to obtain meaningful results. Software tools like R, Python, and EViews facilitate implementation, enabling researchers and practitioners to estimate and analyze MGARCH models effectively.
No Comments